POSTED : November 2, 2021
BY : Raj Nair
Categories: Data & Analytics

MLOps includes the engineering field that specializes in scaling and standardizing the ML lifecycle, ensuring the success of ML models on production systems by applying best practices to ML infrastructure, code, and data.
Building a predictive model to be able to forecast the future from historical data is standard in today’s business environment. But deploying, scaling, and managing predictive models across an enterprise is far from a simple undertaking.
Enterprises hire data scientists to develop end-to-end machine learning (ML) solutions, requiring those data scientists to bridge the gap between scientific methods and engineering processes.
There are some challenges with this approach. Most data scientists are not trained in distributed computing, big data or software engineering, so scaling becomes an issue during feature engineering, algorithm development, and deployment. Additionally, data scientists often develop models without a clearly defined production plan to ensure explainability, scalability, and reproducibility resulting in an expensive and sluggish transition of ML projects from research to production.
MLOps—a combination of machine learning and the DevOps approach—offers a natural solution to these problems.
MLOps grew out of the modern enterprise’s need to provide AI- and ML-powered solutions at scale to their customers. Initially MLOps sought to increase the pace of model development and deployment. Today, MLOps also encompasses the engineering field that specializes in scaling and standardizing the ML lifecycle, ensuring the success of ML models on production systems by applying best practices to ML infrastructure, code, and data.
Our experience has shown that companies hire people with a background and skillset in data science and expect them to accomplish end-to-end machine learning solutions at scale.
Consider the case of a CEO who decides to hire an analytics manager with a PhD in applied mathematics, a statistics background and knowledge in ML algorithms. After nine months, she has created an algorithm with 98% accuracy in the test framework. Performance, however, has declined 30% in the first three months of production. She applied ensemble learning to custom gradient boosting algorithms, so the explainability of the algorithm has become too technical and complicated. As a consequence, the manager decides to discard the project, despite the big investment.
What happened? The analytics manager failed to include a key team member: the MLOps professional who knows how to operationalize and optimize the model at scale. As a metaphor, the CEO hired someone who knows how to build a piano—not someone who knows how to play in front of an audience.
Your enterprise needs professionals who can fill the gap between science and engineering. Working together, data scientists and ML engineers can follow MLOps best practices to ensure success in production systems.
The machine learning lifecycle is an iterative process that ensures that your project is operationalized at scale. It enables collaboration between scientists, engineers, and business stakeholders.
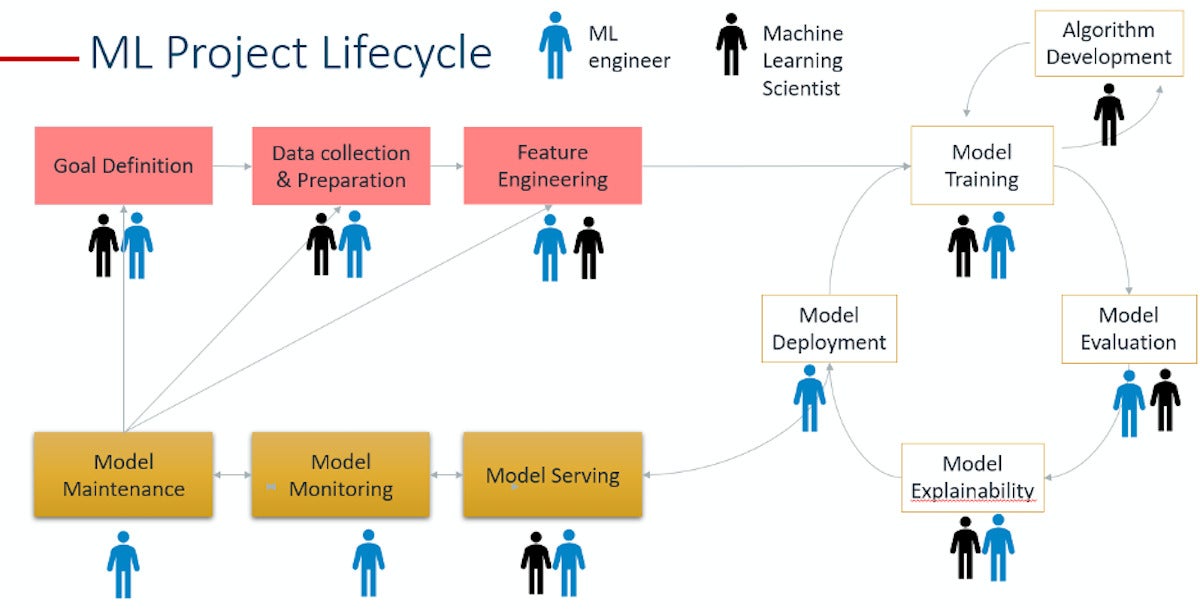
As shown, ML engineers are involved in almost every task. An ML engineer should be able to adopt a “scientific mindset” during different stages of the ML lifecycle—that’s what separates the ML engineer from the data engineer. You can think of the ML engineer as the hybrid specialist between data scientist and data engineer, someone trained in both MLOps and big data engineering.
ML projects are 90% engineering and 10% science. Enabling this proportion in the modern enterprise will require an MLOps team composed of ML engineers who can develop, maintain, scale, and automate an MLOps framework that supports and ensures the success of ML models developed by data scientists.
Finally, AI/ML cannot succeed in the enterprise without the backbone of Enterprise Information Architecture. AI/ML-based outcomes are only as good as the data that feeds them, and many organizations are quickly discovering that the needed information architecture for enterprise AI/ML is lacking. Here are some issues they encounter:
Multiple AI/ML projects are launched across different parts of the enterprise, many requiring potentially the same datasets, but varying age and formats.
AI/ML most often requires access to production data. This means information governance and trustworthiness of the data is of critical importance.
There is an order of magnitude growth in data volumes and data types that traditional architectures are not fit to handle.
Models themselves need to be treated like any other software artifact: governed and managed.
In short, the success of Enterprise AI/ML requires an investment in a scalable, dynamic, and resilient Enterprise Information Architecture.
Learn how Concentrix Catalyst can guide your MLOps journey at catalyst.concentrix.com.
Article originally appeared at CIO.com.
 Raj Nair is VP of Intelligence and Analytics at Concentrix Catalyst. His work includes researching creative solutions to challenging data problems, crafting elegant approaches to scaling data science algorithms and building plug-ins for the big data integration ecosystem.
Raj Nair is VP of Intelligence and Analytics at Concentrix Catalyst. His work includes researching creative solutions to challenging data problems, crafting elegant approaches to scaling data science algorithms and building plug-ins for the big data integration ecosystem.
 Pablo Salvador Lopez is a data scientist at Concentrix Catalyst. He was born and raised in Madrid, Spain and moved to the US three years ago to become a part of the AI revolution. He is a software engineer and mathematician, specializing in Machine Learning, with Big Data and cloud engineering skills.
Pablo Salvador Lopez is a data scientist at Concentrix Catalyst. He was born and raised in Madrid, Spain and moved to the US three years ago to become a part of the AI revolution. He is a software engineer and mathematician, specializing in Machine Learning, with Big Data and cloud engineering skills.