
To develop end-to-end Machine Learning solutions, enterprises hire data scientists who are required to bridge the gap between science methods and engineering processes. However, most Data Scientists are not trained in big data engineering or distributed computing, thus scaling becomes an issue at the stages of feature engineering, algorithm development, and deployment.
Data Science has become too vague. Let’s first understand what the difference is between Data Science and Machine Learning.
What is Machine Learning?
Machine Learning (ML) is not a sub-field of Data Science. ML is a subset of Artificial Intelligence, which started as a sub-field of computer science focused on solving tasks that humans can do, but computers cannot yet do.
Please see the attached chart below to summarize my point of view:
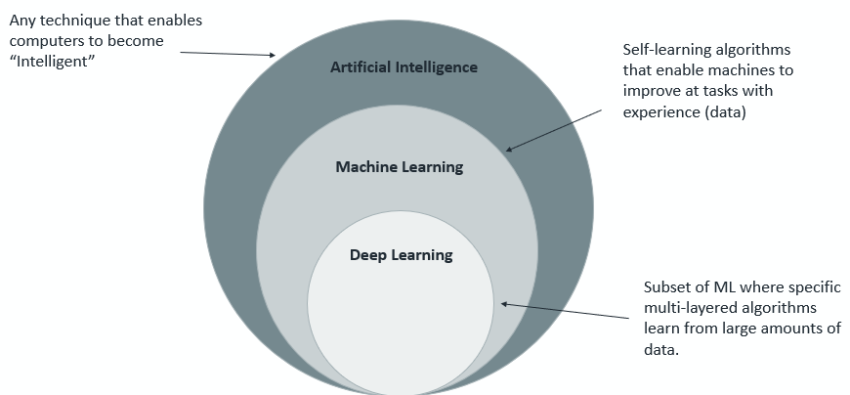
What is Data Science?
Data science is an inter-disciplinary field based on three pillars: Computer Science, Mathematics & Statistics, and Business Knowledge.
This definition is somewhat loose. Data is everywhere and expansive. As a data scientist, I need to solve problems that involve different skill sets and complexity of data. Building complex quantitative algorithms requires a strong quantitative background in statistics linear algebra, data structures, and programming knowledge. Deployment, management, and optimization of data pipelines and infrastructure in order to transform and transfer data requires strong data engineering skills. Translating technical analysis to qualitative action items and effectively communicating their findings to diverse stakeholders requires a high level of communication and business domain knowledge. Intelligently scaling the solution at any stage (model development, feature engineering, ETL, model deployment) requires big data and strong computer science skills.
Therefore, a data scientist is a professional with all of the previously described high-level technical skills necessary to solve critical business problems with data using Machine Learning. If you have these professionals at your company, then you’ve struck gold. Keep them challenged and happy.
However, the world of data keeps evolving and the previous problems are becoming more and more complex. It is time to redefine Data Science and build more specialized teams to ensure ML project success in production.
Building a Successful ML Team
“The Gartner Data Science Team Survey of January 2018 found that over 60% of models developed with the intention of operationalizing them were never actually operationalized.”
Why do only ~25% of data science projects actually make it into production?
Companies hire Data Scientists with completely different backgrounds and sets of skills and ask them to do the same tasks. Let me give you an analogy.
Let’s say that you are celebrating the tremendous success of your company last quarter. You have a wonderful piano at the office so you decided to hire a pianist. He plays it beautifully for hours. Does he know how to build the piano? — The answer is NO. But he knows how it works, so the pianist is capable of producing beautiful melodies.
So, let’s apply this analogy to data. As the Manager in Analytics you hire two Data Scientists to lead an ML practice. Both of them have PhD in applied mathematics with a statistics background and Machine Learning algorithm knowledge. After 9 months, they’ve created an awesome algorithm with 98% accuracy on their test framework. However, performance has declined by 30% percent in the three first months of production. They have applied ensemble learning on custom gradient boosting algorithms so the explainability of the algorithm has became technical and complicated (black box model). Due to the inconsistency of the model outcome on production, you decide to discard the project after a big investment.
What happened? — You failed to include a key team member. The professional that knows how to solve scaling issues, data drift on production, Big Data, MLops best practices and distributed computing. You hired someone who knows how to build the piano but not the one that knows how to play in front of an audience.
“Science is about knowing, engineering is about doing.”
Henry Petroski
You need a professional who fills the gap between science and engineering. A machine learning engineer.
As a result, I see two types of Data Scientists working together. We need to create title distinctions between these two different professionals.
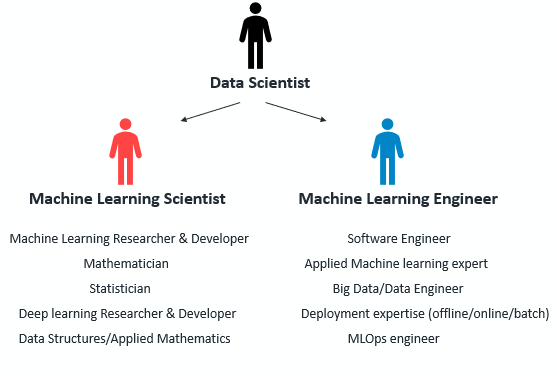
These are disciplines that require distinct “mindsets” — one with a more scientific approach, and another a more practical engineering one. Therefore, I would recommend more specialization of your data scientists in these roles to ensure maximum performance.
Enterprises should hire professionals who align with their business goals. Companies might not need a PhD Data Scientist to reinvent the wheel. In fact, they often hire Machine Learning engineers to train ML algorithms that have already been built, in order to successfully apply machine learning at their companies. Once enterprises have formed an ML team with the right “chefs” — they need to follow a “recipe” aligned with ML best practices to boost the probability of success in production. We’ll talk about this “recipe” in the next section.
Machine Learning Project Lifecycle
The Machine Learning lifecycle is an iterative process that ensures the operationalization of the project at scale. It enables the collaboration between science (ML/DS scientists), engineering(ML engineers), and business domain knowledge (stakeholders). Moreover, it boosts the probability of success with an architecture that delineates the role of each ML team member and manages expectations from the start.
ML project lifecycle is the ultimate “recipe” that allows your ML team to derive practical business value.
Let me to introduce you to our recipe for success.
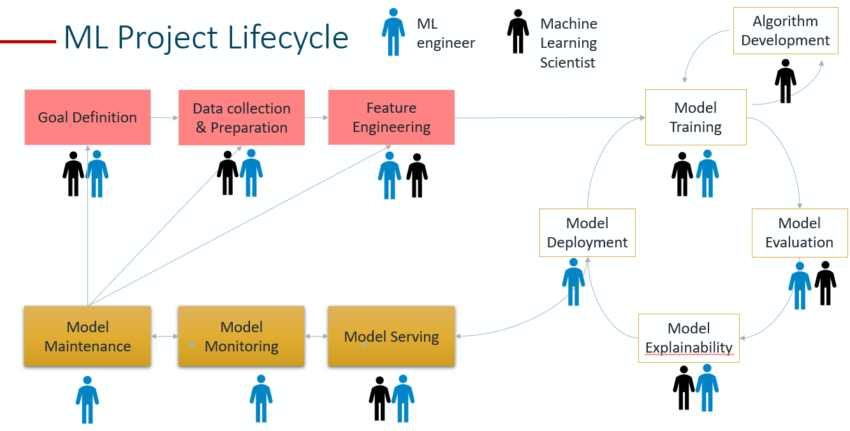
Yes, I know what are you thinking! Quite a number of stages, but no worries — we’ll break it down into three different phases for an easy interpretation.
You can see how the blue figures (ML engineers) are involved in almost every task — I hope you agree with my earlier statement that ML learning project requires 90% engineering and only 10% science. A ML engineer should be able to adopt a “scientific mindset” during model training as well. In fact, I can define a ML engineer as the next-Gen Data Scientist trained in MLOps and Big Data engineering. However, if your company wants to use “out-of the box” algorithms and is able to afford years of research and resources — hire an ML Scientist. Hopefully, he will build you a state-of the-art brand new algorithm.
Phase 1: ML Data Engineering

The ML Project life cycle is an iterative process — therefore every stage is important. A mistake at any stage could be detrimental and obligate the ML team to return to the very beginning of the process. The iteration shouldn’t lead to paralysis. Team members should set the expectations to stakeholders and managers that they can revisit every step along the way in the future.
However, based on my experience Phase 1 is especially important. Goal definition should set realistic expectations among the ML Team and the stakeholders. Data collection preparation and feature engineering stages take up to 80% of the time dedicated to an ML project. Selected features will directly influence the predictive models you use and the results you can achieve.
While designing the pipelines in Phase 1, you need to choose the right tech stack. For example, if you should determine which technology will allow you to scale your computations in the data collection and feature engineering stage. You should take into account the following considerations: Do you need to ingest and process samples of real-time data one observation at a time (online learning) or undergo batch ingestion and processing? What about deployment? Are there low latency requirements? The answers to these question are beyond the scope of this article. However, my point is that — every decision your team makes in Phase 1 will impact the outcome of the project. They could either speed up the other phases or generate bottlenecks.
Phase 2: Model Building and Deployment
This is the most iterative phase of the ML lifecycle. I would like to highlight that before an algorithm gets into the deployment stage, your team needs to ensure that stakeholders understand the model decision-making process and agree upon the most appropriate metric that defines “success”. Model explaninability is a must on this iterative project. It will help stakeholders understand the outcome and also will enable your team to improve the algorithm thanks to a better compression of the algorithm’s behavior.
Phase 3: MLOps

The need of Machine Learning Operation (MLOps)on the ML lifecycle is unquestionable. Traditional software systems were based on deterministic algorithms.
Machine learning is stochastic, not deterministic. We all agreed that ML unlocks a whole new class of tasks. However, non-deterministic software systems (ML algorithms) should be carefully designed and tested.
Here is where I see so many companies failing — The lifecycle of a machine learning model is different from the software development lifecycle (SDLC) in a multitude of ways. Software engineers were testing these traditional software systems before getting to production through a whole testing software infrastructure called Q/A.
“Life changes and so does live data our model takes in,” — Alexander Konduforov acknowledges.
In the stage of model evaluation your ML engineers should have created a testing framework to select the “champion” among the other candidates. Basically they demonstrated that the algorithm works based on the agreed upon metric score at a particular moment. However, once the model is deployed and running in production we need to make sure we understand three concepts:
- Don’t focus only on code versioning, you need a place to save data and model versions. MLOps requires a reporting framework for saving data and model versions to be reused and retrained.
- Algorithms degrade over time, which requires monitoring. MLOps requires you to monitor statistics on inputs(data) and outputs of the model. The goal of the monitor stage is to help ML engineers to build an stable environment.
- Training never ends. Model maintenance stage ensure approaches to identify model degradation. Once the drop in performance is spotted, ML engineers and ML scientist should analyze algorithm behavior and decide to re-train or add more features to enhance performance.
Key Takeaways:
- Machine Learning end-to-end pipeline is the product — not the model itself.
- The goal of any enterprise is to succeed, and to succeed on the ML field, your team needs to specialize. As ML is moving from research to applied business solutions, enterprises need to improve their operation processes. Specialization is the kind of innovation that drives growth.
- Once you’ve designed your ML Team to deliver the mentioned capabilities— they should execute the ML project lifecycle to ensure end-to-end project success on production.
- MLOps has the potential to automate the ML project lifecycle, boost changes of success on production and bridge the gap between science and engineering.
Automation of Machine Learning at scale is the key of any intelligent system. ML is not the future—it is happening right now.
Article originally appeared in Towards Data Science.
Learn how to implement a big data strategy for your organization.